iOS 常见面试题(持续更新)
本篇文章的面试题目来源于自己、实验室同学。还有部分来自网上他人的博客。文章大部分讨论 iOS 方面,也会涉及到计算机网络、操作系统、数据结构等知识。
[TOC]
1 Objective-C 基础部分
1.1 为什么说 Objective-C 是一门动态的语言?
由于runtime这个运行时机制,才为OC增添了动态性,它的动态特性、动态绑定、动态加载等特性,才使得OC成为一门动态语言。
- 动态类型:运行时才会决定对象的类型,比如说 id 类型,任何对象都可以被 id 指针所指,只有在运行时的时候才会决定是什么类型。而静态类型在编译时就能确定时什么类型
- 动态绑定:让代码在运行的时候判断需要调用什么方法
- 动态载入:让程序在运行时添加代码模块以及其他资源
1.2 属性的实质是什么?包括哪几部分?属性默认的关键字有哪些?属性中的 ivar、getter、setter 是如何生成并添加到这个类中?
@property 作为 OC 语言的特性,主要作用就是封装对象。属性有两大部分:实例变量和存取方法(或者是 带下划线的实例变量 + getter + setter 方法),OC语言通常会把所需要的数据保存为各种实例变量,实例变量一般通过“存取方法”来访问。
属性的默认关键字:针对于基本类型,默认为 assign、atomic、readwrite;针对于引用类型,默认为strong、atomic、readwrite
属性的实现:在自动合成的过程中,系统生成了 OBJC_IVAR_$类名$属性名称、setter 和 getter 方法对应的实现函数、ivar_list(成员变量列表)、method_list(方法列表)、prop_list(属性列表)。也就是说,我们每次增加一个属性,系统都会在 ivar_list 中添加一个成员变量的描述,在 method_list 中增加 setter 与getter 方法的描述,在属性列表中增加一个属性的描述,然后计算该属性在对象中的偏移量,然后给出 setter 与 getter 方法对应的实现,在 setter 方法中从偏移量的位置开始赋值,在 getter 方法中从偏移量开始取值,为了能够读取正确字节数,系统对象偏移量的指针类型进行了类型强转。
在 protocol 中使用 property 只会生成 setter 和 getter 方法声明,我们使用属性的目的,是希望遵循我协议的对象能够实现该属性。
在 catagory 使用 @property 也只会生成 setter 和 getter 方法声明。如果我们要给 catagory 中增加属性的实现,需要用到关联变量。
1.3 @dynamic 关键字和 @synthesize 关键字是用来做什么的?
@synthesize :编译器期间,让编译器自动生成存取方法。
@dynamic: 告诉编译器,属性的setter与getter方法由用户自己实现,不自动生成。并且在运行时执行过程中如果找不到对应存取方法,则会报错。这便是 Runtime 中的动态绑定。同时,使用了@dynamic修饰则必须动态生成方法实现。没有@dynamic myName = _myName;的语法,也就是说我们没有办法静态的建立getter/setter并访问下划线前缀的ivar。对应的解决方法是消息转发和动态方法解析
1.4 @synthesize合成实例变量的规则是什么?假如property名为foo,存在一个名为_foo的实例变量,那么还会自动合成新变量么?在有了自动合成属性实例变量之后,@synthesize还有哪些使用场景?
完成属性定义之后,编译器会自动编写访问这些属性所需的方法,此过程叫做“自动合成”。需要强调的是,这个过程由编译器在编译期执行。除了生成方法代码 getter、setter 之外,编译器还要自动向类中添加适当类型的实例变量,并且在属性名前面加下划线,以此作为实例变量的名字。
如 @property NSString *firsrName; 系统会生成一个实例变量,其名称分别为 _firstName。也可以在类的实现代码里通过 @synthesize 语法指定实例变量的名字。 @synthesize firstName = _myFirstName,而不在使用默认的名字。
如果property 名为 foo,存在一个名为_foo 的实例变量,那么不会自动合成新变量。
当以下情况下不会自动合成:
同时重写了 setter 和 getter 、使用了@dynamic 、在 @protocol 、category 中定义的属性、重载的属性
1.5 Objective-C 的属性关键字都有哪些?
常见的属性修饰符:
1. 原子性修饰符:atomic | nonatomic
2. 读写性修饰符:readwrite | readonly
3. 自定义getter | setter 修饰符: getter | setter
4. setter有关修饰符: assign | retain | copy | strong | weak
属性修饰符详解:
• atomic: 原子属性,为setter方法加锁,是系统默认的,保证线程安全,防止线程互斥,但会造成资源消耗。
• nonatomic:非原子属性,多线程并发访问性能高,但是访问不安全;工程开发中大多使用 nonatomic ;使用nonatomic要注意多线程的安全性
• readwrite:读写属性,程序即会创建getter又会创建setter方法,一般系统默认为readwrite。
• readonly:只读属性,程序只会自动创建getter方法。
• assign:表示直接赋值,用于基本数据类型(NSInteger和CGFloat)和C数据类型(如int, float, double, char等)另外还有id类型,这个修饰符不会牵涉到内存管理。但是如果是对象类型,使用此修饰符则可能会导致内存泄漏或EXC_BAD_ACCESS错误
• retain: 针对对象类型进行内存管理。如果对基本数据类型使用,则Xcode会直接报错。当给对象类型使用此修饰符时,setter方法会先将旧的对象属性release掉,再对新的对象进行一次赋值并进行一次retain操作
• copy:主要用在NSString类型,建立一个索引计数为1的对象,然后释放旧对象;系统默认属性是assign。retain是指针的复制,copy是内容的复制
• strong:在 ARC 下,strong类似于retain
• weak:在 ARC 下,weak(弱引用)类似于assign,但 weak 只能修饰类对象,而 assign 修饰的是基本的数据类型。在ARC中,出现循环引用的时候,会使用weak关键字;在自身已经对它进行了一次强引用时,使用weak。
1.6 NSString为什么要用copy关键字,如果用strong会有什么问题?
可变类型是不可变类型的子类,我们可以使用不可变类型接收可变类型。
- 当我们用strong 修饰不可变类型A 时,如果将可变类型B赋值给A,当我们修改B的内容时,A所指向的内容也会随之改变,因为strong只是对创建的对象强引用,并返回当前对象内容地址,因为A和B其实是同一个内容。
- 当我们使用copy 修饰不可变类型A时,如果将可变类型B赋值给A,当我们修改B的内容时,A所指向的内容不会改变,因为这里 copy 修饰的时候会拷贝一份内容,并且返回指针给A,当我们修改B指向的内容时,A 指向的内容是没有发生改变的,因为A 指向的内容和B指向的内存地址是不相同的。
- 当 copy 修饰不可变类型的时候,且使用不可变类型进行赋值,表示浅拷贝,它只是拷贝指针,和strong 修饰一样。
1.7 assign 与 weak 关键字有什么区别?
ARC下,assign 和 weak 是很相近的,都不会使引用计数增加,都能修饰对象类型,但是 weak 比 assign 多了一个功能就是当属性所指向的对象消失的时候(也就是内存引用计数为0)会自动赋值为 nil ,这样再向 weak 修饰的属性发送消息就不会导致野指针操作crash。assign 经常用来修饰基本数据类型。
比如,以下代码:
1 | @property (nonatomic, weak) id weakPoint; |
当程序中的注释被打开时,运行程序有可能会崩溃(有时候不崩溃,你可能需要多运行几次),这是因为当 assign 指针所指向的内存被释放(释放并不等于抹除,只是引用计数为0),不会自动赋值 nil ,这样再引用 self.assignPoint 就会导致野指针操作,如果这个操作发生时内存还没有改变内容,依旧可以输出正确的结果,而如果发生时内存内容被改变了,就会crash。
因此,在 ARC 下,指针变量一定要用 weak 修饰,只有基本数据类型和结构题需要用 assign,例如 delegate,一定要用 weak 修饰。
用 weak 关键字修饰一个 id 类型,如以下这段代码。我们将 字符串赋值给这个id类型,接着我们将这个字符串置为 nil,执行这段代码后,我们会发现除了我们释放的 youString 为 nil 外,其他的不为空。这是因为字符字面值永远不会被释放,所以weak 指针还是指向它。
1 | __strong NSString *yourString = @"Your String"; |
1.8 nonatomic和atomic的区别?atomic是绝对的线程安全么?为什么?如果不是,那应该如何实现?
nonatiomic :非原子性属性,能够提高性能但线程不安全;atiomic:原子属性,能保证线程安全,但是却影响性能,它通过加锁来实现访问/赋值的线程安全。
atomic 不是绝对的线程安全,它只是保证了getter 和 setter 存取方法的线程安全并不能保证整个对象的线程安全。当线程A进行写操作,这时其他线程的读或者写操作会因为该操作而等待。当A线程写完后,B线程继续执行写线程,然后A线程需要读操作时,却获得了在B线程的值,这样就破坏了线程安全。如果有线程C在线程A之前 realease 了该属性,还会导致程序崩溃。
我们应该通过线程锁来保证线程的安全。
1.9 NSCache优于NSDictionary的几点?
NSCache 是一个类似于集合的容器,即缓存,它存储的是键值对,类似于 NSDictionary 类,我们通常使用缓存来临时存储短时间使用但昂贵的对象。重用这些对象可以优化性能,因为它们的值不需要重新计算。
当一个键值对在缓存中时,缓存维护了它的一个强引用。存储在 NSCache 中的通用数据类型通常是实现了 NSDiscardableContent 协议的对象。在缓存中存储这类对象是有好处的,因为当不在需要它时,可以丢弃这些内容,以节省内存。默认情况下,缓存中的NSDiscardableContent 对象在其内容被丢弃时,会被移除出缓存。
NSCache与可变集合的不同点:
- NSCache 类结合了各种自动删除策略,以确保不会占用过多的系统内容;
- NSCache 是线程安全的,我们可以在不同的线程中操作缓存中的对象;
- NSCache 对象不会拷贝 key 对象;
1.10 Objective-C 中, instancetype 与 id 类型的异同点
instancetype 与 id ,都可表示某个方法返回的未知类型的 Objective-C 对象。
在 ARC 环境下,instancetype 用来在编译期确定实例的类型,而使用 id,编译期不会检查类型,运行时检查类型。
在 MRC 下,instancetype 和 id 一样,不做具体类型检查。
id 可以作为方法参数传递, instancetype 不能。
instancetype 可以使那些非关联返回类型的方法返回所在类的类型,而 id 类型只能返回未知类型的对象。
在自定义初始化或者便利构造方法中尽量使用instancetype 作为返回值类型,保证类型安全,它能够确定对象类型帮编译器更好定位代码问题。
1.11 Objective-C 中 self 和 super 的理解,以下代码的输出答案是什么?
1 | // class Son : Father 表示当前类为Son, 父类是 Father |
两个输出的答案都是 Son.
在弄清楚答案,我们需要搞懂 self、super 是什么? [super init] 做了什么?还有我们为什么要 self = [super init]?
self、super是什么?:self 和 super 都是 OC 提供的保留字,self 代表着当前方法的调用者,在 实例方法中, self 代表着“对象”,在类方法中,self 代表着“类”,self 是方法的隐藏的参数变量,指向当前调用方法的对象,另一个隐藏的参数是_cmd,代表当前类方法的 selector。
super 不是隐藏的参数,它只是一个编译器指示符,和self 是指向的同一个消息接受者,查找方法时,指定方法查找的位置在父类。
[super init] 做了什么?
在发送消息时,如
1 | // class A |
如 A a = [[a alloc] init] 调用 [a load] 方法,编译器会将其中的[self message] 转化为 objc_msgSend(id self, SEL _cmd)。此时,self 指代 a 对象,方法从 a 对应类结构的方法调度表中开始寻找,如果找不到,延继承链往父类中寻找;
如果 load 是类方法,self 指代A类对象。编译器会将其中的[self message] 转化为 objc_msgSendSuper(struct objc_super *super, SEL op, ...)。
第一个参数是 objc_super的结构体,第二个参数还是类似上面的类方法 selector,
首先了解一下 objc_super 这个结构体:
1 | struct objc_super { |
用上面的代码为例,当编译器遇到当编译器遇到 A 里 [super message] 时,开始做这几个事:
- 构建 objc_super 的结构体,此时这个结构体的第一个成员变量 receiver 就是 a,和 self 相同。而第二个成员变量 superClass 就是指类 A的 superClass。
- 调用 objc_msgSendSuper 的方法,将这个结构体和 message 的 SEL 传递过去。函数里面在做的事情类似这样:从 objc_super 结构体指向的 superClass 的方法列表开始找 message 的 selector,找到后再以 objc_super->receiver 去调用这个 selector,可能也会使用 objc_msgSend 这个函数,不过此时的第一个参数 theReceiver 就是 objc_super->receiver,第二个参数是从 objc_super->superClass 中找到的 selector
为什么要 self = [super init]
符合oc 继承类 初始化规范 super 同样也是这样, [super init] 去 self 的 super 中调用init super 调用其 super 的 init 。直到根类 NSObject 中的 init ,
根类中 init 负责初始化内存区域 向里面添加一些必要的属性,返回内存指针, 这样延着继承链初始化的内存指针被从上到下传递,在不同的子类中向块内存添加子类必要的属性,直到我们的 A 类中 得到内存指针,赋值给 slef 参数, 在if (slef){//添加A 的属性 }
接下来,回到这个问题,为什么打印结果都一样?
当发送class消息时,不管self和super,其消息主体依然是self,也就是说 self 和 super 指向的是同一个对象。只是查找方法的位置的区别,一个是从本类,一个是从本类的超类。
一般情况下 class 方法 只有在根类 NSObject 中定义,极少情况有子类重写 class 方法,
所以 [slef class] 和 [super class]都是在根类中找方法实现, 消息接收主体又都是 a
自然都打印出 Son
1.12 Objective-C 中 load 和 initialize 方法有什么区别?
load 和 initialize 是 NSObject 的两个特殊的类方法,用于类的初始化。它们有很多共同点,比如;
- 在不考虑主动调用方法的情况下,系统最多调用一次;
- 如果父类和子类都被调用,父类的调用一定在子类之前;
- 调用它们都是为了应用运行时提前创建合适的运行环境
对于 load 方法:
load 方法是当类或分类被添加到 Objective-C runtime时被调用,实现这个方法可以让我们在类加载的时候执行一些类的相关行为,具体如下:
- 调用时机较早,运行环境有不确定因素;在iOS中,通常就是 APP 启动时进行加载,但当 load 调用的时候,并不能保证所有类都加载完成且可用,必要时还要自己负责做 autorelease 处理。
- 对于有依赖关系的两个库中,被依赖的类的load会优先调用。但是在一个库内,调用顺序是不确定的。
- 一个类的load方法不会写明[super load] ,父类就会收到调用,并且在子类之前。
- catagory 的 load 也会收到调用,但是顺序在主类的load调用之后。
- 不会直接触发 initialize 的调用
- 调用类的 load 方法,它是直接使用函数内存地址的方式 (*load_method)(cls, SEL_load); 对 +load 方法进行调用的,而不是使用消息 objc_msgSend 的方式。这种调用方式也就使得子类、分类以及父类的 +load 方法的实现被区别对待了
对于 initialize 方法
+initialize 方法是在类或者它的子类收到第一条消息之前被调用的,这里所指的消息包括实例方法和类方法的调用。也就是说 + initialize 方法是以懒加载的方式被调用的,如果程序一直没有给某个类或者它的子类发送消息,那么这个类的 + initialize 方法永远不会被调用。这样,可以节省系统资源,避免浪费。具体如下:
- initialize 的自然调用是在第一次主动使用当前类的时候(以懒加载的方式)
- 在 initialize 方法收到调用时,运行环境基本健全
- initialize 的运行过程中,是保证线程安全的。
- 和 load 不同,即使子类不实现 initialize 方法,会把父类的实现继承过来调用一遍。
- runtime 使用了发送消息 objc_msgSend 的方式对 +initialize 方法进行调用
1.13 如何令自己所写的对象具有拷贝功能?
若想令自己所写的对象具有拷贝功能,则需要实现 NSCopying 协议。如果自定义的对象有可变和不可变类型,那么就需要同时实现 NSCopying 与 NSMutableCopying 协议。
具体步骤:
- 需要先声明该类遵从 NSCopying 协议。
- 实现 NSCopying 协议,即
- (id)copyWithZone:(NSZone *)zone;
1.14 可变集合类 和 不可变集合类的 copy 和 mutablecopy有什么区别?如果是集合是内容复制的话,集合里面的元素也是内容复制么?
不可变集合类进行 copy之后返回的是不可变集合类,它只是浅复制;不可变集合类进行 mutablecopy 返回的是一个可变的对象,进行了深复制,它们指向的地址不同,内容相同;
可变集合类进行copy,返回一个不可变对象,进行了深复制;可变集合类进行 mutablecopy 时,返回一个可变的对象,并且进行了深复制。
对于集合进行内容复制的话,不论是 copy 还是 mutableCopy,对于其内部元素的拷贝只是浅拷贝。
注意:当使用 copy 修饰一个可变类型时,copy 会复制一个不可变 NSArray 的对象,当添加、删除、修改数组内的元素的时候,程序会因为找不到对应的方法崩溃。
了解更多
1.15 为什么代理要用 weak ? 代理的 delegate 和 dataSource 有什么区别? block 和代理的区别?
我们定义的指针默认都是 _strong 类型的,strong 类型的指针会造成强引用,必定会影响一个对象的生命周期,这就形成了循环引用。

上图中,由于代理对象使用强引用指针,引用创建的委托方LoginVC对象,并且成为LoginVC的代理。这就会导致LoginVC的delegate属性强引用代理对象,导致循环引用的问题,最终两个对象都无法正常释放。
我们将LoginVC对象的delegate属性,设置为弱引用属性。这样在代理对象生命周期存在时,可以正常为我们工作,如果代理对象被释放,委托方和代理对象都不会因为内存释放导致的Crash。
代理的 delegate 侧重于与用户交互的回调;datasource 侧重于数据的回调。
代理主要由三部分组成:
协议: 用来指定代理双方可以做什么,必须做什么,通过 @protocol 实现协议。
代理:根据指定的协议,完成委托方需要实现的功能。
委托:根据指定的协议,指定代理去完成什么功能。

协议只能定义公用的一套接口,类似于一个约束代理双方的作用。但不能提供具体的实现方法,实现方法需要代理对象去实现。协议可以继承其他协议,并且可以继承多个协议,在iOS中对象是不支持多继承的,而协议可以多继承。
协议有两个修饰符@optional和@required,创建一个协议如果没有声明,默认是@required状态的。这两个修饰符只是约定代理是否强制需要遵守协议,如果@required状态的方法代理没有遵守,会报一个黄色的警告,只是起一个约束的作用,没有其他功能。
在 iOS 中,代理的本质就是代理对象内存的传递和操作,我们在委托类设置代理后,实际上只是用一个 id 类型的指针将代理对象进行了一个弱引用。委托方让代理方执行操作,实际上是在委托类中向这个id类型指针指向的对象发送消息,而这个id类型指针指向的对象,就是代理对象。

通过上图发现,其实委托方的代理属性本质上就是代理对象自身,设置委托代理就是代理属性指针指向代理对象,相当于代理对象只是在委托方调用自己的方法,如果没有实现就会导致崩溃。
代理和Block的区别:
上面也详细的介绍了代理,而 Block 就是带截获自动变量的匿名函数,我们也可以使用 block 进行回调。对于,它们的区别,我们还是针对使用场景细说:
- 多个消息传递时,应该使用 delegate
- 一个委托对象的代理属性只能有一个代理对象,如果想要委托对象回调多个代理对象,应该使用 block.
- 代理是可选的,而block 在方法调用的时候只能通过将某个参数传递一个 nil 进去。
- 代理更加面向过程,block 则更加面向结果
- 从性能上,block 的性能消耗要略大于 delegate ,因为 block 会涉及到栈区向堆区的拷贝等操作,时间和空间上的消耗都大于代理。而代理只是定义了一个方法列表,在遵守协议对象的objc_protocol_list中添加一个节点,在运行时向遵守协议的对象发送消息即可。
2. iOS 基础部分
2.1 iOS 中常见的设计模式都有哪些?
在 iOS 设计模式中,总共有超过二十种的设计模式。我们常用的主要有代理、通知、单例、策略等设计模式。
- 代理:简单的来说,就是委托其他帮助自己做事,它为其他对象提供了一种代理,以控制对这个对象的访问。代理模式由三部分组成:协议、委托和代理。iOS 中我们的协议可以是@optional和@required的。
- 观察者:常见的比如 KVO、通知,就是一种观察者模式,它定义了对象之间一种一对多的依赖关系。一般,我们对于 model层的数据进行监听,并在不同的界面进行了注册,然后当这个状态发生改变的时候,会通知所有的观察者对象。
- 单例模式:单例模式使得类中的一个对象成为系统中的唯一实例,它提供了对对类的对象所提供的资源的全局访问点。因此,需要用一种只允许生成对象类的唯一实例的机制。如系统提供的 UIApplication、NSUserdefault 等都是单例类。
- 策略模式:定义了一系列的算法,把它们一个个封装起来,使得它们可以相互替换。它易于理解且易于切换扩展。
- 中介者模式:用一个对象来封装一系列对象的交互方式,中介者使各个对象不需要显式的相互作用,从而使得耦合松散,独立的改变它们之间的交互。
2.2 讲一下你理解的 MVC 和 MVVM、MVP ?
MVC(模型-视图-控制器):Model 层,模型对象,负责封装应用程序的数据,定义操控和处理数据的逻辑和运算;View 层视图对象负责显示来自model 层的数据,并对用户的操作作出响应;Controller 控制器对象在 MVC 设计模式中充当M 层和 V 层交互的媒介,它将来自M层的数据交由V层显示,并将V层的用户操作产生的新的数据或者更改过的数据传达给模型对象。
在 MVC 中,M 和 V 是不能够直接通信的,只能通过 C 来传递;C 可以直接与 M 层对话,而M层通过通知和KVO机制与C层间接通信;C 也可以直接与V层对话,V层通过 action 向 C层报告事件的发生,C层是V层的直接数据源。C层是V层的代理,以便同步V和C。
MVC暴露出来的问题:C层的过于臃肿,M层的轻便,以及网络逻辑的归属。
MVP(模型-视图控制器-协调器):M层与MVC的M相似,都是负责封装数据,用来封装网络请求获取的json数据的集合;V 层可以是 View视图,也可以是viewController等控件;P层,作为M和V的中间人,从M层获取数据之后传给V层,使得V和M没有耦合。
MVVM:MVVM将ViewController视作View,View 层与 ViewModel 之间进行绑定;VM是 UIKit 下的每个控件以及控件的状态。VM调用会改变M的同时将M的改变更新到自身并且在V上更新状态(因为我们绑定了V 和 VM)
2.3 iOS 中的看门狗机制是什么?
为了避免应用陷入错误状态导致界面无响应,Apple 设计了看门狗(WatchDog)机制。一旦超时,强制杀死进程。
在不同的生命周期,触发看门狗机制的超时时间有所不同。
看门狗超时崩溃报告:
异常类型:00000020异常代码:0x8badf00d
在网络应用程序中看门狗超时崩溃的最常见原因是主线程上的同步网络。这里有四个影响因素:
- 同步网络: 这是您发出网络请求并阻止等待响应的地方
- 主线程:同步网络通常不太理想,但如果在主线程中执行,会导致特定的问题。因为主线程负责运行用户界面,如果你很长时间内阻塞了主线程,用户界面变得无法接受无法响应。
- 长时间超时: 如果网络刚刚消失(例如,用户正在进入隧道的列车中),则任何待处理的网络请求都不会失败,直到超时过期。大多数网络超时都是以分钟为单位来衡量的,这意味着主线程上阻塞的同步网络请求可以使用户界面一次不响应数分钟。
- 看门狗 - 为了保持用户界面的响应,iOS包含一个看门狗机制。如果您的应用程序无法及时响应某些用户界面事件(启动,挂起,恢复,终止),则看门狗将会终止您的应用程序并生成看门狗超时崩溃报告。监督人员给你的时间没有正式记录,但总是少于网络超时。
这个问题的一个棘手方面是它高度依赖于网络环境。如果你总是在你的办公室测试你的应用程序,那里的网络连接性好,你永远不会看到这种类型的崩溃。但是,一旦您开始将应用程序部署到最终用户 - 谁将在各种网络环境中运行它 - 这样的崩溃将会变得很普遍。
2.4 说一下 iOS 应用程序的启动执行都经历了哪些步骤?应用程序包含几种状态?
首先,了解一下下面这张图

- main 函数:程序的入口函数,它的函数内部
@autoreleasepool { return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class])); }
就是这段代码。 可以看到就执行了UIApplicationMain 函数。 - UIApplicationMain 函数的几个参数:
1 | /* @param argc 系统参数 |
UIApplicationMain 函数的作用:UIApplicationMain会根据函数第三个参数创建 UIApplication对象,根据第四个参数创建一个 delegate对象,并将该 delegate 对象赋值给 UIApplication 对象中的 delegate 属性。接着会建立应用程序的 Main RunLoop,进行事件的处理。
- 事件处理时,首先会在程序完毕后调用 delegate 的
didFinshLaunchingWithOptions:方法。APP 启动的时候,会调用 info.plist 文件,看是否指定了 main.storyboard ,如果设置了就去加载 main.storyboard。如果没有设置,就需要我们去手动创建 UIWindow(它作为一个容器,容纳所有的 UIView,并且 UIWindow会将事件消息传递给 UIView)。 - 接下来就是控制器以及控制器view的创建,,具体可以了解控制器的生命周期。
从上面的这个流程,我们可以发现它包括五种状态:
- Not running(未运行):程序未启动
- Inactive(未激活):其他两个状态切换时出现的短暂状态。当用户锁屏或者系统提示用户去响应 Alert窗口(如来电、信息等)时
- Active(激活):在屏幕下显示正常的运行状态,该状态下可以接受用户输入并及时更新显示
- Background(后台)::程序在后台且能执行代码。用户按下Home键不久后进入此状态(先进入了 Inactive状态,再进入Background状态),然后会迅速进入挂起状态(Suspended)。有的程序经过特殊的请求后可以长期处于Backgroud状态
- Suspended (挂起):程序在后台不能执行代码。普通程序在进入Background状态不久后就会进入此状态。当挂起时,程序还是停留在内存中的,当系统内存低时,系统就把挂起的程序清除掉,为前台程序提供更多的内存
2.5 UIView、CALayer 以及 UIWindow 有什么区别?
UIView 与 CALayer 区别:
- 事件响应:UIView 和 CALayer 最终都是继承自 NSObject,但是 UIView 直接继承自 UIResponder, 正是因为这层继承,才可以让UIView 可以响应事件。
- View 和 Layer 的 Frame 映射:一个 Layer 的 frame 是由它的 anchorPoint、position、bounds 和 transform 共同决定,而一个 View 的 frame 只是简单的返回 Layer 的 frame,同样 View 的 Center 和 Bounds 只是直接返回layer 对应的 Position 和 Bounds。在初始化view的时候,会调用私有方法[UIView _cretaelayerWithFrame] 去创建 CALayer
- UIView 主要是对显示内容的管理,而CALayer 主要侧重于显示内容的绘制:UIView 是 CALayer 的 CALayerDelegate ,在 View 显示的时候,UIView 作为 Layer 的 CALayerDelegate,view 的显示内容由内部的 CALayer display。
- 在做 iOS 动画的时候,修改非 rootLayer 的属性会默认产生隐式动画,而修改UIView 则不会。
UIWindow 是 UIView 的子视图,UIWindow 在应用中是作为根视图来承载UIView的。UIWindow提供一个区域(一般就是整个屏幕)来显示UIView,并且将事件分发给UIView。一个应用一般只有一个UIWindow,但特殊情况也会创建子UIWindow。
详细的,可以阅读这篇博客
2.6 谈谈你对 UIResponder 的响应者链的理解。
响应链是由一系列链接在一起的响应者组成的。一般情况下,一条响应链开始于第一响应者,结束于application对象。如果一个响应者不能处理事件,则会将事件沿着响应链传到下一响应者。
在 APP 中,所有的视图是按照树状层次结构组织起来的。
当用户触发某一事件后,UIKit 会创建一个事件对象,并且会被放入一个事件队列中,按照先进先出的顺序来处理。当处理事件时,UIApplication 对象会从队列头部取出一个事件对象,并将其分发出去。通常是将事件先分发给程序的主 window 对象,window对象会首先尝试将事件分发给触摸事件发生的那个视图上。系统使用hit-testing来找到触摸下的视图,它检测一个触摸事件是否发生在相应视图对象的边界之内(即视图的frame属性,这也是为什么子视图如果在父视图的frame之外时,是无法响应事件的)。如果在,则会递归检测其所有的子视图。包含触摸点的视图层次架构中最底层的视图就是hit-test视图。在检测出hit-test视图后,系统就将事件发送给这个视图来进行处理。
2.7 iOS 触摸事件都经历了什么?
首先,苹果会注册一个 source1 (基于 mach port)用来接收系统事件。
当我们用手指触摸屏幕时,首先 IOKit.framework 会生成一个 IOHIDEvent 事件并由 SpringBoard 接收,SpringBoard 用 mart port(IPC进程间通信) 转发给需要的 APP 进程,随后苹果注册的 source1 事件就会内部触发 source0 回调 _UIApplicationHandleEvent() 进行应用内分发。接着进行 source 0 回调,内部封装 IOHDEvent 为 UIEvent,把事件加入 UIApplication 管理事件队列中,调用 UIApplication 的 sendEvent 方法将 UIEvent 传给 UIWindow。接着事件会按照 UIApplication -> UIWindow -> SuperView -> SubView 的顺序检测,检测调用的方法为 hitTest 和 pointInside。
整体经历了四个大过程:
- 起始阶段: CPU处于睡眠状态、等待事件 -> 产生事件
- 系统响应阶段: 屏幕硬件感应到事件、传递到 IOKit -> 将事件封装为 IOHIDEvent对象 -> IOKit 通过IPC(进程间的通信)将事件给 SpringBoard(iOS 系统桌面)
- SpringBoard 响应阶段:Spring 主线程的 RunLoop 接收到 IOKit -> 唤醒RunLoop,触发 Mart Port的 Sorce1 回调 -> SpringBoard 检测是否有App在前台,若有,SpringBoard 则通过 IPC 转发给对应的 App。若没有,则自身触发 Source0 回调 。
- APP 内部响应:前台 App 主线程的 RunLoop 收到 SpringBorad 转发来的消息并苏醒,触发对应 Mach Port的Source1 回调 -> Source1 回调,内部触发 Source0 回调__UIApplicationHandleEventQueue() -> Source0 回调,内部封装 IOHIDEvet 为 UIEvent,把事件加入 UIApplication 管理的事件队列中,调用 UIApplication 的 sendEvent 方法将 UIEvent 传给了 UIWindow -> 事件会按照 UIApplication -> UIWindow -> SuperView -> SubView 的顺序不断的检测,检测的方法为 hitTest 和 pointInside。
2.8 谈谈VC的生命周期? viewWillAppear一般什么时候调?什么时候view出现了,但appear却没调?(父子关系、window、前后台)
VC的生命周期:VC 生命周期的第一步是初始化,但是具体调用方法还有所不同。如果使用 StoryBoard 来创建 ViewController ,我们不需要显式地去初始化,Storyboard 会自动使用 initWithCoder: 进行初始化。如果不使用 StoryBoard,我们可以使用 init:函数进行初始化,init: 函数在实现过程中还会调用 initWithNibName:bundle:。
初始化完成后,VC 的生命周期会经过下面几个函数:
loadView --> viewDidLoad --> viewWillAppear --> viewWillLayoutSubviews --> viewDidLayoutSubviews --> viewDidAppear --> ViewWillDisapper --> ViewDidDisappear --> dealloc
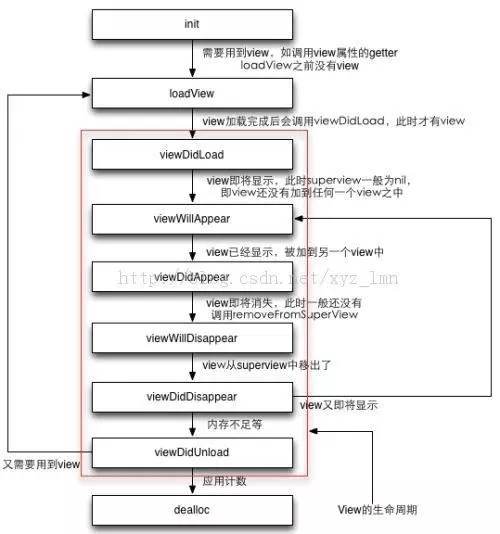
loadView 方法是用来负责加载VC的View的,我们可以自定义VC的View。VC的View是通过懒加载的方式进行加载的,当我们需要使用到view时,就会调用控制器view的get方法,在get方法内部,,首先判断 view 是否已经创建,如果已存在,则直接返回存在的 view,如果不存在,则调用控制器的 loadView 方法,在控制器没有被销毁的情况下,loadView 也可能会被执行多次。
在 iOS 4 & 5 中 ViewController 中有一个 viewDidUnload 方法。当内存不足,应用收到 Memory warning 时,系统会自动调用当前没在界面上的 ViewController 的 viewDidUnload 方法。 通常情况下,这些未显示在界面上的 ViewController 是 UINavigationController Push 栈中未在栈顶的 ViewController,以及 UITabBarViewController 中未显示的子 ViewController。这些 View Controller 都会在 Memory Warning 事件发生时,被系统自动调用 viewDidUnload 方法
在 iOS 6 之前,viewDidUnload 方法被废弃,应用受到 memory warning 时也不会再调用viewDidUnload 方法,我们可以通过重载 -(void)didReceiveMemoryWarning 和 -(void)dealloc 来进行清理工作。
viewWillAppear 总是在 viewDidLoad 之后被调用,但不是立即,当你只是引用了属性 view,却没有立即把 view 添加到任何已经展示的视图上时,viewWillAppear 不会被调用,这在 view 被外部引用时,就会发生。当然,随着 ViewController 的多次推入,多次进入子页面后返回,该方法会被多次调用。与 viewDidLoad 不同,调用该方法就说明控制器一定会显示。 切换前后台不会调用 viewWillAppear
2.9 iOS 多线程都有哪些?你在什么地方用过?
考察:三种多线程技术,以及各自的区别。你在什么地方使用,就是考虑你对与各自使用场景的了解。
iOS 有 三种多线程编程的技术,分别是:
NSThread、NSOperation 和NSOperationQueue 、GCD 三种形式
NSThread 比另外两个轻量级,但是需要自己管理线程的生命周期、线程同步
Operation Queue 建立在 GCD 的基础上,面向对象,相对于 GCD 来说,使用 Operation Queue 会增加一点额外开销,我们可以给 operate 之间添加依赖关系、可以取消一个正在执行的operation、暂停和恢复 operation queue等。
GCD:是一种更轻量级的,以FIFO的顺序执行并发任务的方式,使用 GCD 我们不用关心任务的调度情况。
GCD 与 NSOperation 的区别主要表现在以下几方面:
- GCD是一套 C 语言API,执行和操作简单高效,因此NSOperation底层也通过GCD实现,这是他们之间最本质的区别.因此如果希望自定义任务,建议使用NSOperation;
- 依赖关系,NSOperation可以设置操作之间的依赖(可以跨队列设置),GCD无法设置依赖关系,不过可以通过同步来实现这种效果;
- KVO(键值对观察),NSOperation容易判断操作当前的状态(是否执行,是否取消等),对此GCD无法通过KVO进行判断;
- 优先级,NSOperation可以设置自身的优先级,但是优先级高的不一定先执行,GCD只能设置队列的优先级,如果要区分block任务的优先级,需要很复杂的代码才能实现;
- 继承,NSOperation是一个抽象类.实际开发中常用的是它的两个子类:NSInvocationOperation和NSBlockOperation,同样我们可以自定义NSOperation,GCD执行任务可以自由组装,没有继承那么高的代码复用度;
- 效率,直接使用GCD效率确实会更高效,NSOperation会多一点开销,但是通过NSOperation可以获得依赖,优先级,继承,键值对观察这些优势,相对于多的那么一点开销确实很划算,鱼和熊掌不可得兼,取舍在于开发者自己;
7)可以随时取消准备执行的任务(已经在执行的不能取消),GCD没法停止已经加入queue 的 block(虽然也能实现,但是需要很复杂的代码)